Defer x Vercel:
From experiments to thriving products
We are happy to officially roll out our Vercel Integration for 80% of users and customers using NextJS. The Defer Vercel Integration provides a direct link between Vercel and Defer projects with environment variables bidirectional sync:
Deliver great user experiences with Defer and NextJS
Vercel's Framework-defined infrastructure principles have greatly inspired our mission to make queueing and background tasks easy to get started with and to manage at scale:
const algoliaIndex = algoliaClient.initIndex('INDEX_NAME'); async function algoliaUpdateAllArticles() { const now = new Date() const articles = await prisma.articles.findMany({ where: { updatedAt: { lt: now, gte: previousFriday(now) } } }); await algoliaIndex.replaceAllObjects( articles.map((article) => articleToSearchObject(article) ); await prisma.articles.update({ where { id: { in: articles.map(a => a.id) }}, data: { updatedAt: new Date() } });} export default defer.cron(algoliaUpdateAllArticles, "0 0 * * *");
While Vercel helps you keep your app performant with Edge Functions, Edge caching, and Edge Databases, Defer closes the loop by enabling you to remove all non-necessary work outside your users' journey.
For example, the following server-side actions, while being related to a user action, should not slow down the UI feedback:
- Schedule rich emails and notifications
- Process uploaded documents
- Update a batch of Stripe subscriptions
- Updating an Algolia search index
- Triggering some LLM embedding work
Beyond user-perceived performance, all the above server-side actions, depending on external APIs or processing, are fragile and can degrade your end-user experience.
You can strengthen your Next.js app reliability and responsiveness by moving all those use cases in the background with Defer.
Defer for LLM, from experiments to products
Adding LLM capabilities to an app or building one with NextJS goes beyond chatting with OpenAI API:
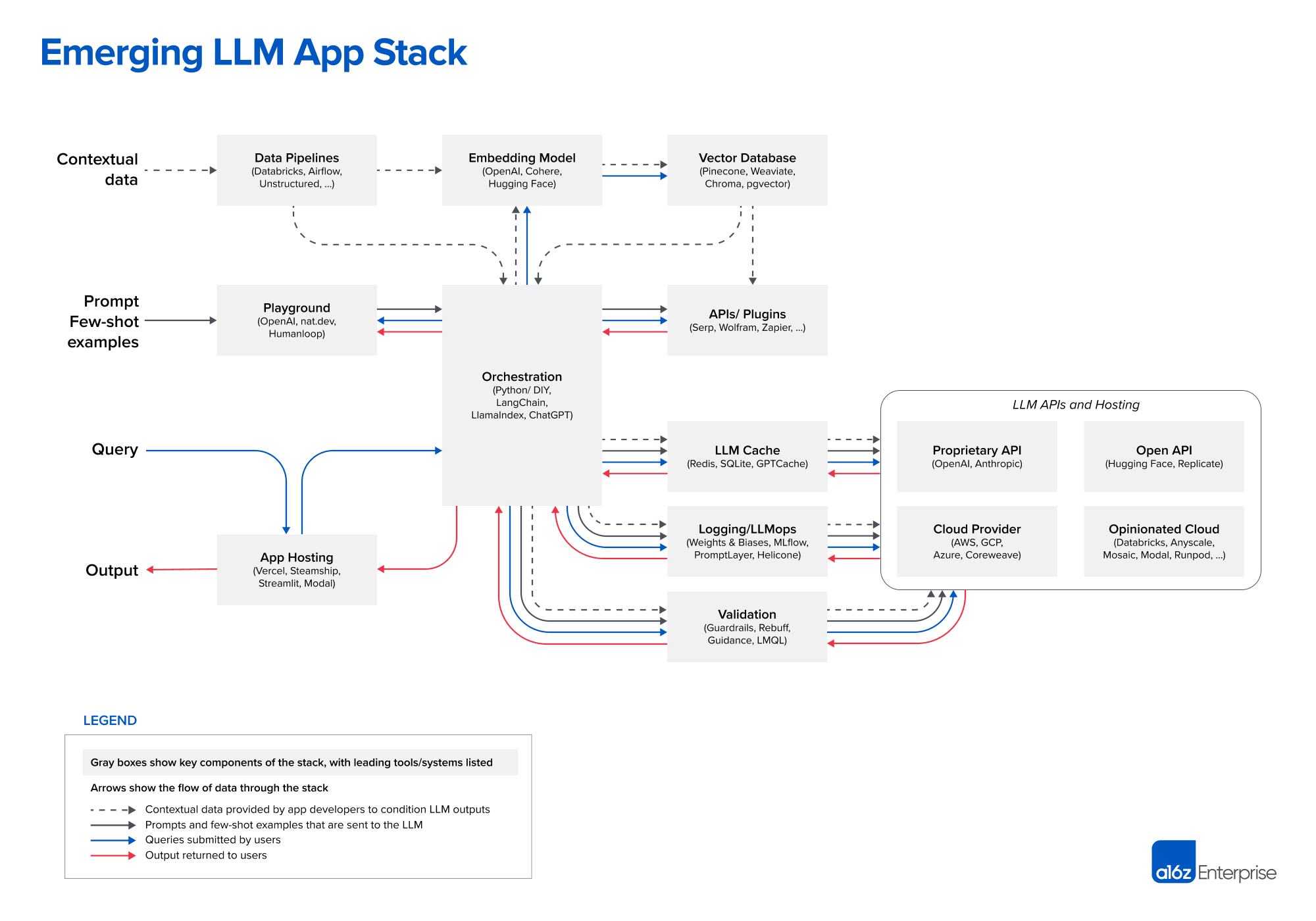
The non-interactive remaining part of the LLM stack iceberg is essential to any thriving LLM application: generate embeddings on your application's data, set up workflows to chain and mix different sources of data and LLMs, trigger user notifications based on vector search, and fine-tune an Open AI model.
Defer enables you to extend your LLM use cases capability while staying in your NextJS application and keeping the same velocity while experimenting.
On the way to production, Defer will help you to scale your LLM applications with flexible computing, no duration limitation, advanced scheduling capabilities (concurrency, retries, and more), and integrations with LLM observability tools.
Explore some guide
Defer helps dealing with long-running data work
Use Defer to stream and process files with LLM
Defer and NextJS Server Actions: perfect match
Defer DX perfectly fits with NextJS Server Actions: no queues or events to deal with, just simple functions calls:
"use server" import { defer } from "@defer/client" export default defer( async function sendNotification(notification: EmailNotification) { // ... send a notification with Resend ... }, { concurrency: 10, retry: 2 })
Like NextJS Server Actions, Defer Background Functions should have serializable arguments and return value.
"use server" import sendNotification from "../../defer/sendNotification" export async function sendFriendRequest(userId: string) { // ... business logic ... await sendNotification(notification) // will be performed on Defer}
We now safely remove any failure risk and added latency to our Server Action by deferring the notification in the background with Defer.
"use client" import { sendFriendRequest } from "./actions" export function UserProfile({ userId }) { const sendFriendRequestWithId = sendFriendRequest.bind(null, userId) return ( <form action={sendFriendRequestWithId}> <button type="submit">Send friend request</button> </form> )}
Get started
Related articles
Defer Runners are now available in Europe
Benefit from Defer Platform's new region
Defer x RedwoodJS: the definitive builders' stack
Defer is joining forces to extend the great RedwoodJS toolset with easy to set up and reliable background jobs.