A deep dive into
Function's retry strategies
Configuring Retries for your background function is an essential feature.
As many use cases are subject to the randomness of functions' execution (3rd party API errors, data inconsistencies, or unexpected errors) and impact the end-user experience, it is vital to set up the proper retries configuration.
This article covers three use cases along with three distinct retry strategies.
TLDR: Check out our "Retries cheatsheet" at the end of the article.
- Default configuration: no retries
- Calling 3rd-party APIs: exponential-backoff retries
- Workflows: fixed linear retries
- Delivering webhooks, emails, notifications: long-span exponential retries
Default configuration: no retries
By default, Defer background functions get a { retry: false } configuration:
import { defer } from "@defer/client" async function myBgFunction() { /* ... */} export default defer(myBgFunction)// is equivalent to:export default defer(myBgFunction, { retry: false })
Retries get disabled by default to prevent:
- unwanted retries of long-running executions - that might affect your usage
- unwanted side effects - due to non-idempotent functions
Idempotency is a function that can run multiple times without unwanted side effects.
For example, a function that creates a new user should ensure to use a database transaction to not commit the changes in case of failure. If not, the function's retry execution will result in a duplicate user record in the database.
However, providing a retry configuration is essential, as most executions failure should not be treated as a final state. Failures might be related to external errors such as API downtime, API rate-limiting, system issues, or temporary unwanted state.
In such cases, providing a retry strategy to your background functions will improve their resilience.
Calling 3rd-party APIs: exponential-backoff retries
Interacting with 3rd party APIs exposes your background functions to multiple external failures:
- API reliability issues: the requested 3rd party API might face some downtime.
- API rate limiting errors: you might trigger a spike of requests that should be retried later.
- Data consistency errors: you might request some data that is not yet available, resulting in errors in your function.
For these reasons, most background functions interacting with 3rd party APIs require a retry strategy, but which one?
The best practice to handle external failures is to space the retries in time to avoid an "over-accident".
Such a pattern is called exponential-backoff retries, exponential standing for the growing space put between each new retry occurrence, as showcased below:
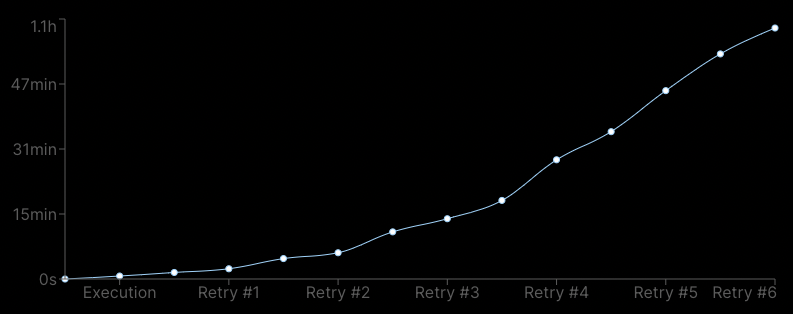
Adding the { retry: true } configuration to your background function will enable a default exponential-backoff retries configuration that will retry your execution up to 13 times.
While retrying an execution on such a long span (the 13th retry would occur 75min after the initial execution time) is relevant for some specific use cases (see "Sending webhooks") but not for most 3rd party API interaction use cases.
For this reason, prefer the { retry: 5 } configuration that will retry your execution - with exponential backoff - up to 5 times (the 5th retry would occur 7min after the initial execution):
import { defer } from "@defer/client" async function myBgFunction { /* ... */ } // `importHubspotContacts()` will now benefit// from exponential back-off retriesexport default defer(importHubspotContacts, { retry: 5})
Tips: How to handle 3rd party API rate-limiting
The retry combined with concurrency is a simple way to deal with API rate-limiting.
For example, the below function - running for 500ms - will ensure that the 3rd party API will be called only once per second:
import { defer } from "@defer/client" async function importHubspotContacts() { /* ... */} export default defer(importHubspotContacts, { retry: 5, concurrency: 2,})
The combination of retry and concurrency is perfect for fixed API rate limiting.
However, many public 3rd party APIs rely on dynamic rate limiting using the leaky bucket algorithm and others.
For this reason, we will soon roll out a throttling option to better configure rate limiting.
Workflows: fixed linear retries
Workflows are a set of background functions working together to perform a complex and vital operation such as onboarding, LLM workflows, or document generation.
Any workflow failure needs to happen fast to inform the end user - or support team - as soon as the required action to move forward.
Consider the following user onboarding workflow:
import { delay, defer } from "@defer/client"import { sendWelcomeEmail, importContactsFromHubspot, sendTutorialsEmailIfNoActions,} from "./defer" async function userOnboarding(user: User) { await Promise.allSettled([ awaitResult(importContactsFromHubspot)(user), awaitResult(sendWelcomeEmail)(user), ]) // Once the Hubspot data is synced // and the welcome mail sent, // let's flag the user as onboarded await prisma.user.update({ where: { id: user.id }, data: { onboarded: true }, }) const sendTutorialsEmailIn1Day = delay( sendTutorialsEmailIfNoActions, "1 day" ) await sendTutorialsEmailIn1Day(user)} export default defer(userOnboarding)
The userOnboarding() workflow has many possible points of failure:
- We can fail to contact the Hubspot API
- Or fail to send the welcome email
Issues that could lead to a terrible user onboarding experience.
So, how do we configure retries on workflows?
Workflows and retries work similarly to Error boundaries in React.
Child background functions should not configure retries and throw errors that bubble up to the workflow.
By failing, the workflow will retry and run from the beginning.
Let's now add our retry configuration to the userOnboarding() workflow.
As stated earlier, workflows should be retried as fast as possible, meaning that we don't want to space retries exponentially but linearly, as shown below:
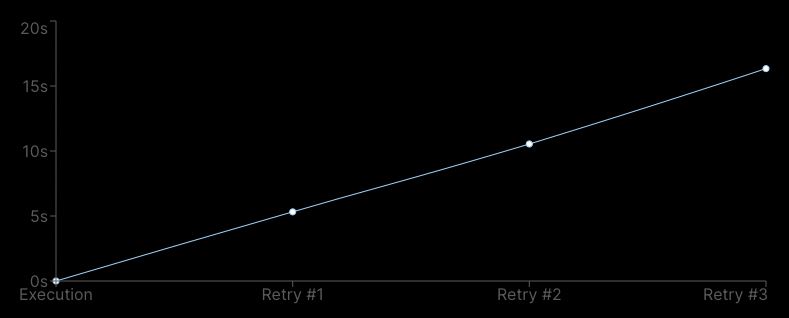
We want to retry the workflow immediately, up to 3 times in a row (here, considering that userOnboarding() fails after 5 secs every time).
Which is configured as follows:
import { delay, defer } from "@defer/client"import { sendWelcomeEmail, importContactsFromHubspot, sendTutorialsEmailIfNoActions,} from "./defer" async function userOnboarding(user: User) { // ...} export default defer(userOnboarding, { // we want to retry up to 3 times maxAttempts: 3, // we should retry immediately initialInterval: 0, // No a random space between retries randomizationFactor: 0, // No exponential spacing of retries multiplier: 0,})
This retry strategy also applies to plain background functions known to be “flaky”.
For example, background functions relying on puppeteer, system calls, or flaky dependencies.
Delivering webhooks, emails, notifications: long-span exponential retries
While delivering webhooks, emails, and notifications sounds similar to interacting with 3rd party APIs, another aspect of your application's reliability is at stake.
Failing to deliver such data does not impact an end-user but another system (another application), which can have a more significant impact.
For this reason, we want to increase the number of retries and span them longer to allow the target system to recover.
As stated earlier, the { retry: true } configuration is a shorthand for 13 exponential back-off retries, with the first occurring at 30 secs and the last (13th), 75 min after the initial execution time.
This configuration is excellent for delivering emails and notifications (to end-users).
However, when it comes to sending data (webhooks) to another system, we might want to follow the industry standard, as Shopify does:
Shopify will retry 19 times over 48 hours and completely delete your webhook subscription once all attempts are exhausted as opposed to Stripe, which will attempt to deliver your webhooks for up to three days with exponential backoff.
Here is how to configure an exponential backoff retry that goes up to 48 hours when delivering a contact update from a CRM application:
async function contactUpdated(changes: ContactChanges) { // ... fetch("https://example.com/callback" /* ... */) // ...} export default defer(contactUpdated, { // we want to retry up to 13 times maxAttempts: 13, // a first retry should occur after 30secs initialInterval: 30, // randomize the space between retries randomizationFactor: 0.5, // apply a growing space between retries multiplier: 1.5, // last retry should be at 2 days max maxInterval: 60 * 24 * 3,})
Retry options playground
All the covered use cases showcased the different ways to configure Retries on a background function.
The { retry: false }, { retry: true }, { retry: 5 } are shorthands to disable retries or quickly configure exponential back-off retries.
The interactive Retry configurator below is the perfect tool to play and understand the role of each retry option:
1{2 // How many retries should we attempt in total?3maxAttempts:,4 // How close the first retry should be? (in seconds) ?5initialInterval:,6 // How much randomness should be introduced in the space between retries?7randomizationFactor:,8 // How fast the space between each retry should grow? (exponential back-off)9multiplier:,10 // What should be the max space between 2 retries? (in seconds)11maxInterval:,12}
Retries cheatsheet
Retries are a core building block of reliable APIs to ensure that external APIs and other external systems behaviors don't impact your end-user experience.
When enabling retries on a background function, ensure that a retry execution won't lead to a side effect (ex: duplicated user creation in the database) by leveraging try/catch {} to introduce some idempotency.
The Retries cheatsheet below is a good starting point for your future background functions and to retrospect on your existing ones:
Related articles
Build Week #1: Wrap up
This first Build week has been the opportunity to share all the issues that Defer is solving for Serverless and LLM applications as well as when building complex no-code user experiences.